# Top 7 AWS cost-saving strategies
> How to save big in AWS by cleaning up your underused resources, stale data, and more.
By Bob Tordella
Published: 2022-05-05
As users of cloud services we aim to pay for only what we use. But without active monitoring and governance, it's all too easy to overspend -- by as much as 70% according to [Gartner](https://aws.amazon.com/blogs/aws-cloud-financial-management/good-intentions-dont-work-but-cost-control-mechanisms-do/). In this post we suggest 7 strategies to help you identify and act on AWS cost-saving opportunities.
## 1. Overused resources
AWS resources can be overused in a few different ways. When you have long-running resources, consider if they can be stopped intermittently. In non-production environments, for example, it can make sense to spin up resources when needed, or only during working hours.
Another kind of overuse: overprovisioning. Do you really need more than one load balancer in an account, for example? Such resources can unintentionally multiply when added by different automation pipelines, or because architecture patterns change over time.
Similarly, deployment automation can result in more CloudTrails than you need. The first one in each region is free, additional trails can accrue unnecessary cost.
## 2. Underused resources
Large EC2 (or RDS, Redshift, ECS, etc) instances may have been created and sized to handle peak utilization but never reviewed later to see how well the storage, compute, and/or memory is being utilized. Consider rightsizing the instance type if an application is overprovisioned in any of these ways. AWS has different pricing for resources that are compute-optimized or memory-optimized. Analyze your inventory and utilization metrics to find resources that are underused, and prune them as warranted.
## 3. Abandoned resources
It's possible to end up with resources that aren't being used at all. Load balancers may not have associated resources or targets; RDS databases may have low or no connection counts; a NAT gateway may not have any resources routing to it. And, most commonly, EBS volumes may not be attached to running instances. The ability to easily create, attach and unattach disk volumes is a key benefit of working in the cloud, but it can also become a source of unchecked cost if not watched closely. Even if an Amazon EBS volume is unattached, you are still billed for the provisioned storage.
It's very common during development, and when working with ephemeral workloads, to create and destroy large numbers of VMs. The default console setting will detach, but not delete, storage volumes when instances are destroyed. It can seem risky to delete random volumes you didn't create ("what if someone needs it for something?"); meanwhile, dozens or hundreds of unused disks pile-up from inaction and improper handling. Checking for abandoned resources is a crucial cost-saving strategy.
## 4. Generation gaps
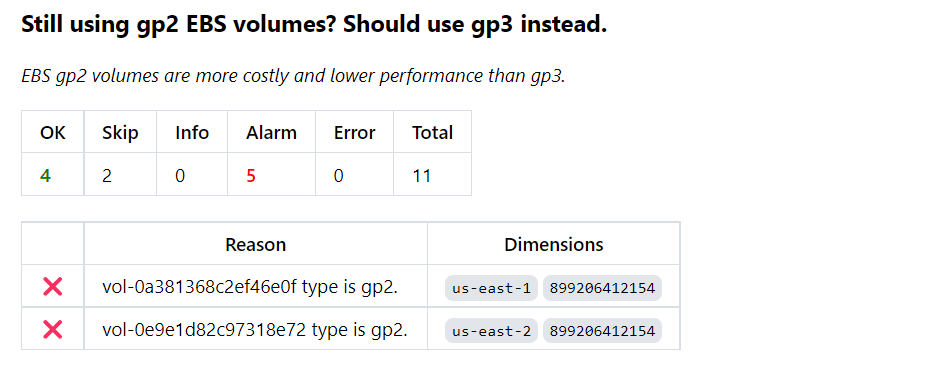
It's often true that a new generation of cloud resources delivers better performance and capacity at a lower unit price. We've elsewhere documented [huge savings](https://turbot.com/blog/2020/12/aws-ebs-cost-savings/) when moving from the previous generation of EBS volumes, `gp2`, to the current generation, `gp3`. You can realize up to 20% cost saving with `gp3` and enjoy higher performance too.
The same theme applies to EC2, RDS, and EMR instance types: older instance types should be replaced by latest instance types for better hardware performance. In the case of RDS instances, for example, switching from the M3 generation to M5 can save over 7% on your RDS bill.
Upgrading to the latest generation is often a quick configuration change, with little downtime impact, that yields a nice cost-saving benefit.
## 5. Stale data
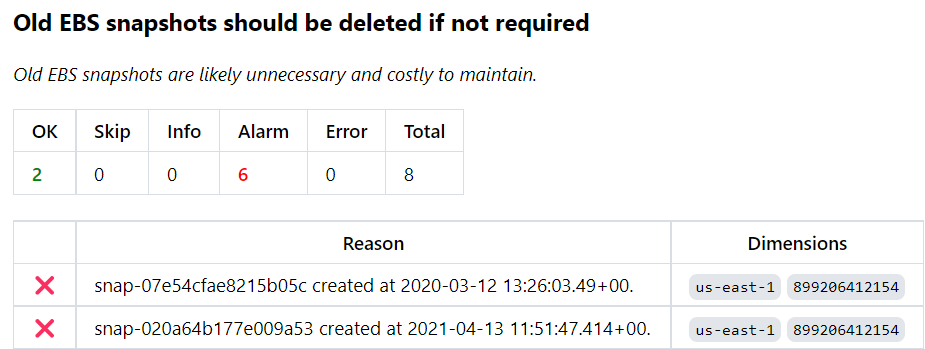
It's great to be able to programmatically create backups and snapshots, but these too can become a source of unchecked cost if not watched closely. It's easy to delete an individual snapshot with a few clicks, but challenging to manage snapshots programmatically across across multiple accounts. Over time, dozens of snapshots can turn into hundreds or thousands.
How long should EBS snapshots be retained? How long can data in a DynamoDB table remain unchanged? You'll want to set policies that define when data becomes stale, and review snapshots or tables that exceed those limits.
In some cases it may make sense to move to another storage tier. If you don't need low latency or frequent access, for example, you can save money by switching from S3 to S3 Glacier.
## 6. Capacity planning
If you have long-running resources, it's a good idea to prepurchase reserved instances at lower cost. This can apply to long-running resources including EC2 instances, RDS instances, and Redshift clusters. You should also keep an eye on EC2 reserved instances that are scheduled for expiration, or have expired in the preceding 30 days, to verify that these cost-savers are in fact no longer needed.
That said, long-term commitments come with caveats. AWS evolves constantly: new generation types appear, prices change. Your app architecture and usage are always changing too. Planning ahead one year makes sense, but it's hard to plan for a longer horizon, things change too quickly in the cloud.
## 7. Cost variance
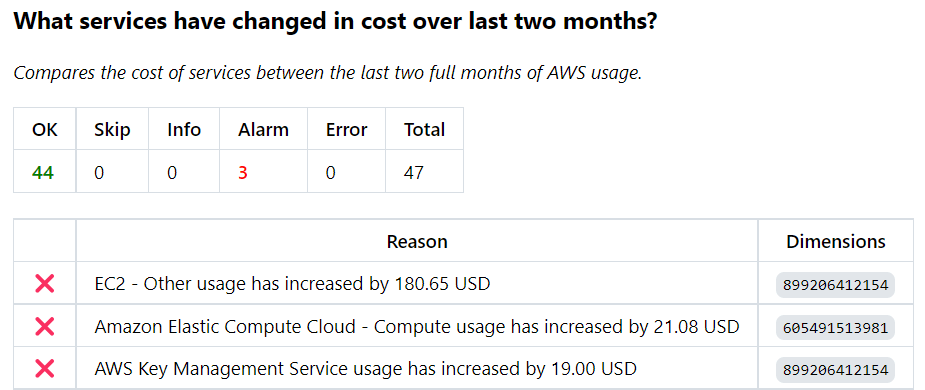
Have your per-service costs changed more than allowed between this month and last month? You'll want to pay close attention to cost spikes. When there's been an increase, can the app owner explain why? Often it's a surprise to the app owner, so just asking the question can help either justify the cost or prompt review and optimization.
## Be thrifty in your use of AWS
[AWS Thrifty](https://hub.steampipe.io/mods/turbot/aws_thrifty) helps you find these types of cost-saving opportunities and more. In [Use Steampipe to identify cost savings in AWS](https://steampipe.io/blog/control-cost-with-aws-thrifty) we cover AWS Thrifty basics, showing how to run individual controls, benchmarks, or the whole suite. The strategies we've called out in this post are woven through AWS Thrifty; we offer them here to help you think strategically about cost-effective use of AWS.
If you're also using other clouds, you'll want to check out our [full suite](https://hub.steampipe.io/mods?objectives=cost) of mods for cost control. In addition to AWS we provide cost controls for Alibaba Cloud, Azure, Digital Ocean, GCP, and Oracle Cloud.