# Using SQL to check spreadsheet integrity
> The CSV plugin brings spreadsheet data to Steampipe. We show how to write compliance checks for that data.
By Jon Udell
Published: 2021-11-03
We have a love/hate relationship with our spreadsheets. We love them because they're convenient, and we hate them because they're uncontrolled. With the [0.9 release](https://steampipe.io/blog/release-0-9-0) of Steampipe we can now apply integrity checks to our spreadsheet data. The new [CSV plugin](https://hub.steampipe.io/plugins/turbot/csv) is the enabler for this magic. Building on dynamic schema support in Steampipe, the CSV plugin is first of a new kind of plugin that maps data to tables without requiring predefined schemas.
## Fixed vs dynamic schemas
Previously, every Steampipe plugin worked with a fixed schema. The [Slack](https://github.com/turbot/steampipe-plugin-slack) plugin, for example, consumes Slack's REST API to [tables](https://hub.steampipe.io/plugins/turbot/slack/tables) using definitions from the [golang API wrapper](https://github.com/slack-go/slack) for Slack. That wrapper defines a `User` with a fixed set of fields: `ID`, `TeamID`, `Name`, etc. The Slack plugin maps those fields to the columns you see when you `select * from slack_user`.
The CSV plugin doesn't need such fixed schemas: it builds them on the fly. That means you can acquire tables from any source that exports data to CSV files. You can query these separately; you can join across them; and you can join CSV-sourced tables with fixed-schema tables provided by other plugins.
## Granular resource tagging
Suppose you're using Steampipe to check resource tags against a vocabulary of mandatory tags. In [our 0.8 release](https://steampipe.io/blog/release-0-8-0) we introduced a way to specify that list of tags when running one of the [tagging control mods](https://hub.steampipe.io/mods?objectives=tags) for AWS, Azure, or GCP. In the AWS context, for example, you can do this.
```
steampipe check benchmark.mandatory --var \
'mandatory_tags=["Application", "Environment", "Department", "Owner"]'
```
That command runs 71 [controls](https://steampipe.io/docs/reference/mod-resources#control), each of which interpolates the list of tags passed on the command line, and checks each of associated resources for those tags.
What if you want to augment the general rule with checks for specific tags associated with specific resources? You can now record a mapping from resources to resource-specific tags in a spreadsheet, export it to CSV, and write new controls that join against the mapping table defined in that CSV file.
## Integrity checks for spreadsheets
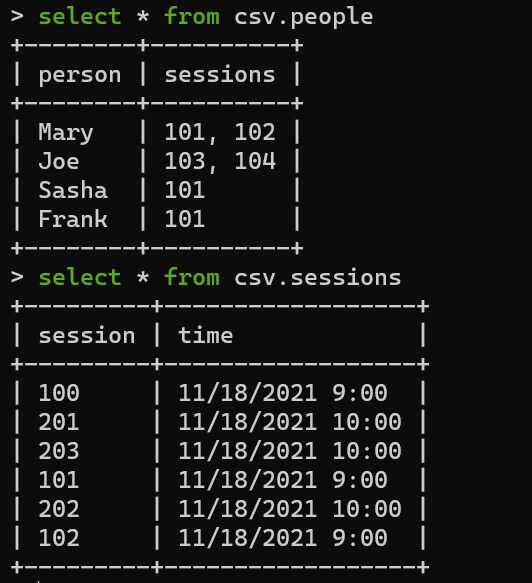
Beyond augmenting existing Steampipe queries and controls, you can now write new ones to explore and validate the data in critical spreadsheets. For example, here's a common scenario: an event planner uses a spreadsheet to keep track of people and sessions. The spreadsheet has two tabs like so.
```
person,sessions
Mary,"101, 102"
Frank,101
Joe,"103, 104"
Sasha,101
```
```
session,time
100,11/18/2021 9:00
101,11/18/2021 9:00
102,11/18/2021 9:00
201,11/18/2021 10:00
202,11/18/2021 10:00
```
To work with this data in Steampipe, export the spreadsheet tabs to files: `people.csv` and `sessions.csv`. Then install the CSV plugin (`steampipe install plugin csv`), edit `~/.steampipe/config/csv.spc`, and set `paths` to include to the folder containing the files (in this case, `~/csv`).
```
connection "csv" {
plugin = "csv"
paths = [ "~/*.csv" ]
}
```
Now, when you run `steampipe query`, those files magically appear as tables in the `csv` namespace.
 ## Writing custom controls to check data integrity
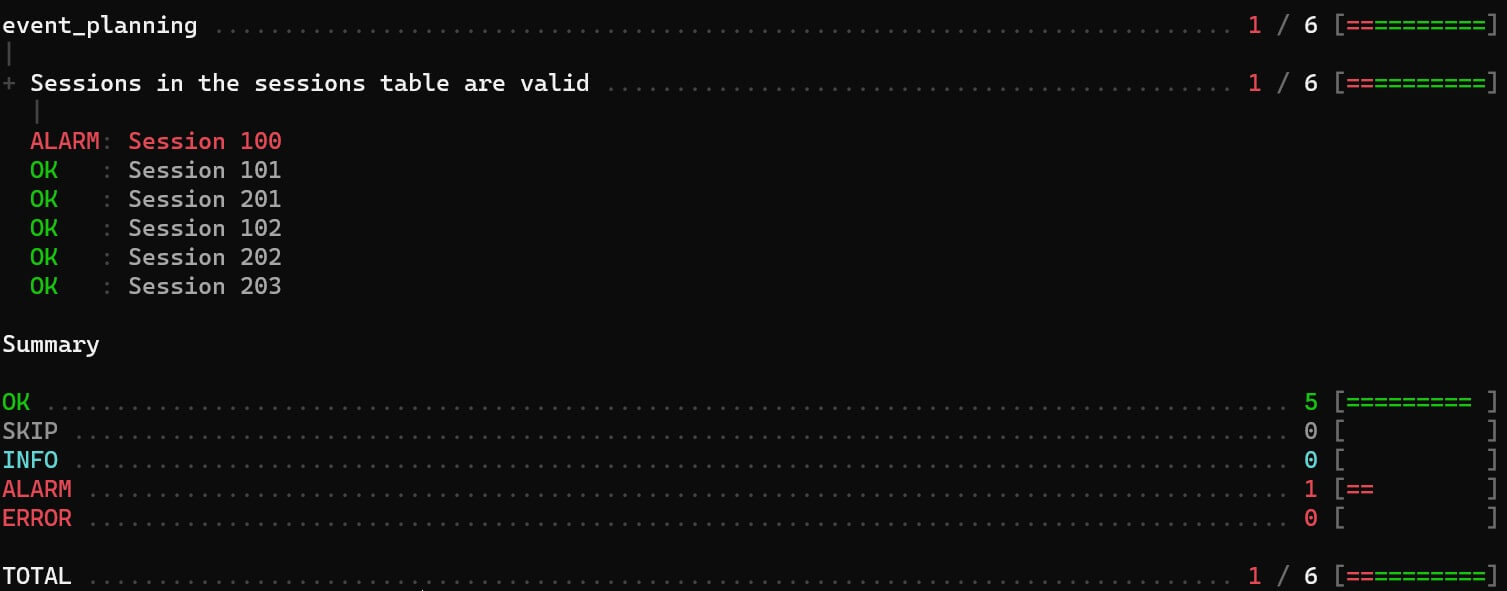
As is typical in such scenarios, nothing guarantees that the session numbers are valid. Let's say that the valid sessions are 101-105 and 201-205. Here is a control that checks that condition.
```
control "sessions_valid_in_session_table" {
title = "Sessions in the sessions table are valid"
sql = < A Steampipe mod is a portable, versioned collection of related Steampipe resources such as queries, controls, and benchmarks. Steampipe mods and mod resources are defined in HCL, and distributed as simple text files. Modules can be found on the Steampipe Hub, and may be shared with others from any public git repository.
Mods can be very elaborate. The [AWS compliance mod](https://hub.steampipe.io/mods/turbot/aws_compliance), for example, comprises 10 benchmarks that encapsulate 433 controls and 224 named queries.
## Writing custom controls to check data integrity
As is typical in such scenarios, nothing guarantees that the session numbers are valid. Let's say that the valid sessions are 101-105 and 201-205. Here is a control that checks that condition.
```
control "sessions_valid_in_session_table" {
title = "Sessions in the sessions table are valid"
sql = < A Steampipe mod is a portable, versioned collection of related Steampipe resources such as queries, controls, and benchmarks. Steampipe mods and mod resources are defined in HCL, and distributed as simple text files. Modules can be found on the Steampipe Hub, and may be shared with others from any public git repository.
Mods can be very elaborate. The [AWS compliance mod](https://hub.steampipe.io/mods/turbot/aws_compliance), for example, comprises 10 benchmarks that encapsulate 433 controls and 224 named queries.
But they can also be very simple. If our `event_planning.sp` file contains only the code shown above, we can do this to find invalid sessions in the `sessions` table.
```
~/event_planning$ steampipe check all
```
## Checking a more complex table
We also want to know if the sessions mentioned in the `people` table are valid. In order to do that, we'll need to project each list of sessions to a set of rows.
```
with person_session as (
select
person,
string_to_array(
regexp_replace(sessions, '\s', '', 'g'),
','
) as sessions
from csv.people
)
select
person,
unnest(sessions) as session
from
person_session
```
```
+--------+---------+
| person | session |
+--------+---------+
| Joe | 103 |
| Joe | 104 |
| Mary | 101 |
| Mary | 102 |
| Frank | 101 |
| Sasha | 101 |
+--------+---------+
```
The `regexp_replace` function strips whitespace so that each session id won't include any spaces. The `string_to_array` function then turns that string value into an array. These steps will be familiar to everyone whose used Python, or another language, to clean and reshape data.
If you're coming from Python, you can read `regexp_replace` as `re.sub` and `string_to_array` as `split`. The `unnest` function, though, will be less familiar. It projects a Postgres array to rows, so we end up with multiple rows for Joe and Mary.
Given this setup, here's a control that checks for valid sessions in the `sessions` table. We use `select distinct` because we don't need to check duplicate occurrences of a session.
```
control "sessions_valid_in_people_table" {
title = "Sessions in the people table are valid"
sql = <
## Conclusion
Dynamic schemas vastly expand the universe of data available to Steampipe. The CSV plugin was the first to exploit the new capability, but already there's another. With the [AirTable plugin](https://hub.steampipe.io/plugins/francois2metz/airtable), contributed by François de Metz, you can bring tables from that system into Steampipe.
If there weren't an AirTable plugin, of course, you could export to CSV and use the CSV plugin. CSV is truly the lingua franca of data exchange; all kinds of systems and apps can export it; the folks at [GitTables](https://gittables.github.io/) are annotating and studying 1.7 million tables extracted from CSV files in GitHub!
You can use CSV-sourced data to augment queries and controls that work with Steampipe's growing collection of [plugins](https://hub.steampipe.io/plugins). But as we've seen here, you can also write simple controls to check the integrity of critical data that's managed, for better and worse, in spreadsheets. Our [Steampipe samples repo](https://github.com/turbot/steampipe-samples) has the ingredients shown here. Install the CSV plugin, run the controls, then show us how you've used this method to check the integrity of one of your spreadsheets!